環境
python 3.9.0+ macos Big Sur 11.2.3+ Google Chrome 89.0.4389.114
python包 : pandas,re
正文
python的re包是自帶包,该包中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分 Pandas就更加厉害了,该包是为了解决数据分析的功能而出现的。Pandas 纳入了大量库和一些标准的数据模型,有效的提供了操作大型数据集所需的方法。用了他之后你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
获取数据集合的信息
我在这里先读取在上次爬取中获取到的数据集,也就是上一次最后写入的json文件 读取到json文件后,我们可以看一看pandas分析的数据效果。json字符串很长我就不打印了,但是我们可以看看data.info()
if __name__ == '__main__':
data = pandas.read_json('pythonData.json')
data.info()
这个是指通过pandas包去读取一个json的数据集。数据文件名根据自己所定,我肯定是根据上次写入的文件数据来获取(pythonData.json)
pandas把所有数据读取之后,通过info()函数可以获取这个数据集的信息
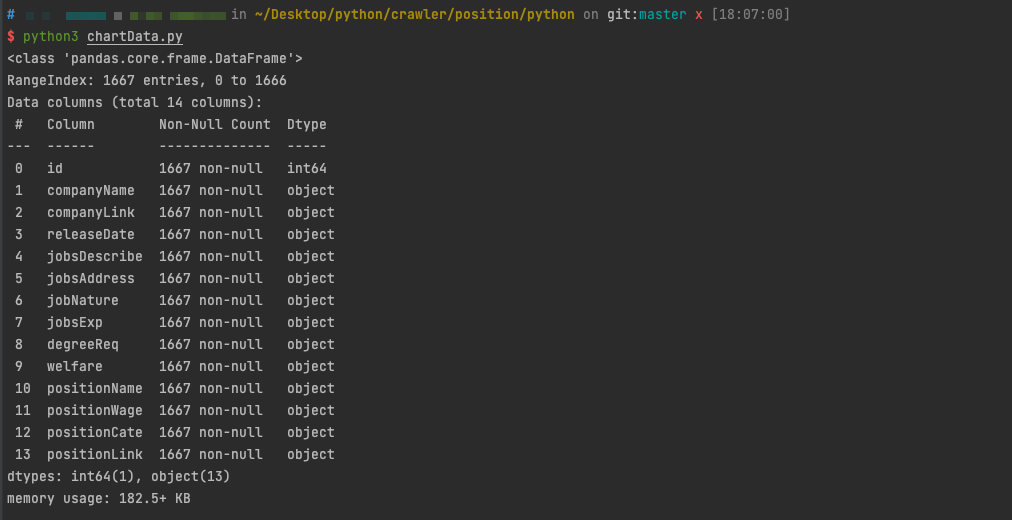 如图所示,data是一个pandas里的DataFrame格式的文件,类似于excel中的表格,本质上其实是一个方便数据处理的二维数组。 整个data中有1667行数据、14列,其中id一列是我自己添加的索引id
如图所示,data是一个pandas里的DataFrame格式的文件,类似于excel中的表格,本质上其实是一个方便数据处理的二维数组。 整个data中有1667行数据、14列,其中id一列是我自己添加的索引id
生成Excel表格
然后我直接通过函数把数据生成一个xls数据表
if __name__ == '__main__':
data = pandas.read_json('newData.json')
data.to_excel('pythonData.xls')
结果导出来的文件我发现多了一列没有字段名的数据。这是为什么呢,这是pandas读取数据的时候,自动安排了索引,所以这列多出来的字段其实就是索引。 那么我就把索引设定为自己生成的id,并且删除这一列,我再导一次就发现正常了。一定要删除,要不就会出现两列id的数据
if __name__ == '__main__':
data = pandas.read_json('newData.json')
data.index = data['id']
del(data['id'])
data.to_excel('pythonData1.xls')
 其实走到这一步,很多Excel大神已经拿Excel给我生动的上了一课,可是我是个Excel渣渣啊。所以只能用代码来做数据处理了
其实走到这一步,很多Excel大神已经拿Excel给我生动的上了一课,可是我是个Excel渣渣啊。所以只能用代码来做数据处理了
数据清洗
首先什么是数据清洗。不是已经获取了很多数据了吗。这些数据不能用吗,为什么要清洗呢。 数据清洗顾名思义就是把数据中的“脏东西”的“洗掉”,这是什么意思呢,就是指发现并纠正数据中可识别性错误,包括检查数据一致性啊,处理无效值啊和缺失值等。因为数据获取方式的问题很多数据可能产生的并不一致,可能会出现各种意外,这样就避免不了有的数据是错误数据,有的数据相互之间会有冲突,这些错误或者冲突的数据显然是我们不想要的,这些就叫做“脏数据”。而我们要做的就是让程序按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。
就比如表格這裡的jobsAddress这个字段,显示的是 城市-区-县这样的格式。但是我们只需要城市就好了,有的可能数据抓取的时候就是好的,而有的就是没有,这个时候我们就需要清洗这一组数据了。通过pandas和正则其实很好做好这一项工作,代码如下
import pandas
import re
class Draw:
def __init__(self):
self.data = pandas.read_json('newData.json')
'''
重組排序規則,使用自己的id作為索引
'''
self.data.index = self.data['id']
del (self.data['id'])
dfSort = self.data.sort_index()
self.data = dfSort
def cityDataRinse(self):
self.data['jobsCity'] = self.data['jobsAddress']
# 正则匹配字符 - 前面的所有字
pattern = re.compile('(.*?)(\-)')
dfCity = self.data['jobsAddress'].copy()
for i in range(len(dfCity)):
item = dfCity.iloc[i].strip()
result = re.search(pattern2, item)
if result:
dfCity.iloc[i] = result.group(1).strip()
else:
dfCity.iloc[i] = item.strip()
self.data['jobsCity'] = dfCity
return self.data
if __name__ == '__main__':
data = pandas.read_json('newData.json')
draw = Draw()
data = draw.cityDataRinse()
res = data1[['companyName','jobsCity','jobsAddress']].head(10)
print(res)
然后我们就会发现我们清洗后的数据生成了jobsCity一列,并且如我们所想的只有城市。输出如图

这一系列的操作就是把我所不需要的数据变成了我想并且需要的数据。这个操作就叫数据清理
----------end
本文为ctexthuang原创文章,转载请注明来自ctexthuang_blog

