環境
python 3.9.0+ macos Big Sur 11.2.3+ Google Chrome 89.0.4389.114
python包 : requests,time,math,os,json
正文
首先先需要確定自己要收集什麼数据资料,打開数据来源的某網站(某勾网,lagou,以下文章皆用某网站代替)。打开后发现,如果不登录無法進行数据的查询工作。(某宝也是)這該怎麼辦呢。 解決的方法当然有很多,但是這裡我只用了最简单的方法去做。以后有时间再谢谢复杂性质的。 我這裡的解決方法只是通過查看某网站的登录态是用的哪個參數识别的,在爬蟲请求数据的時候把這個參數帶入進去請求就可以了
####请求参数构造
先在浏览器打开某网站之后,我们F12打开控制台选择NetWork,然后进行一次搜索请求。就会发现出现非常多行的文件或资源请求结果。我们先筛选一下请求的type,看看有没有接口式的数据,这样的话我们就不用去抓取整个页面也不用做正则去截取数据源了
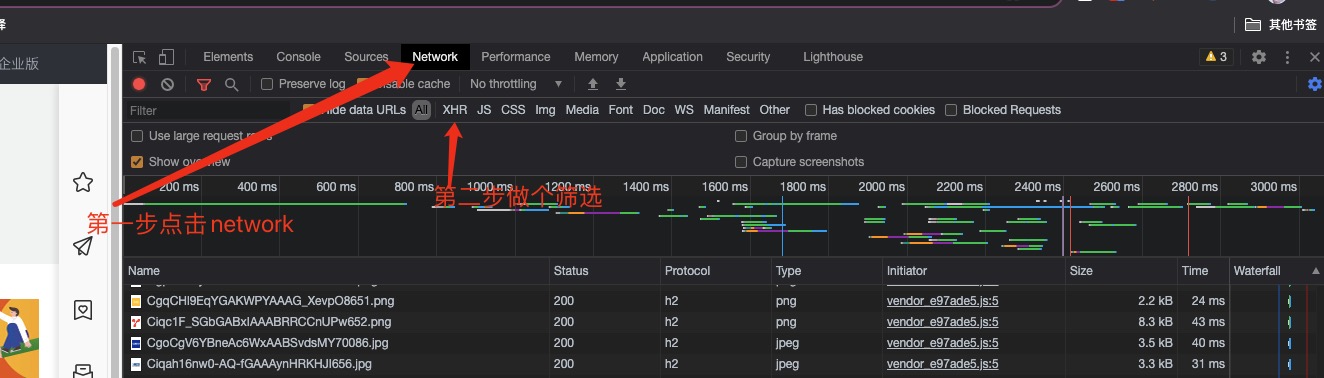
XHR全称XMLHttpRequest,用于与服务器交互数据,是ajax功能实现所依赖的对象,jquery中的ajax就是对XHR的封装。 找到这个接口文件,并看到数据结果返回集
那确定是这个接口后,就开始分析请求头和请求参数
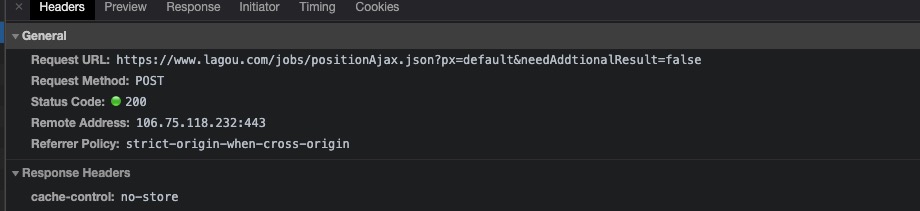
首先我看到Request URL中的就是请求接口的地址,先不理?符号后面带的参数,所以完整的请求接口就是https://www.lagou.com/jobs/positionAjax.json,其次我通过Request Method可以知道是一个POST请求。在继续往下分析
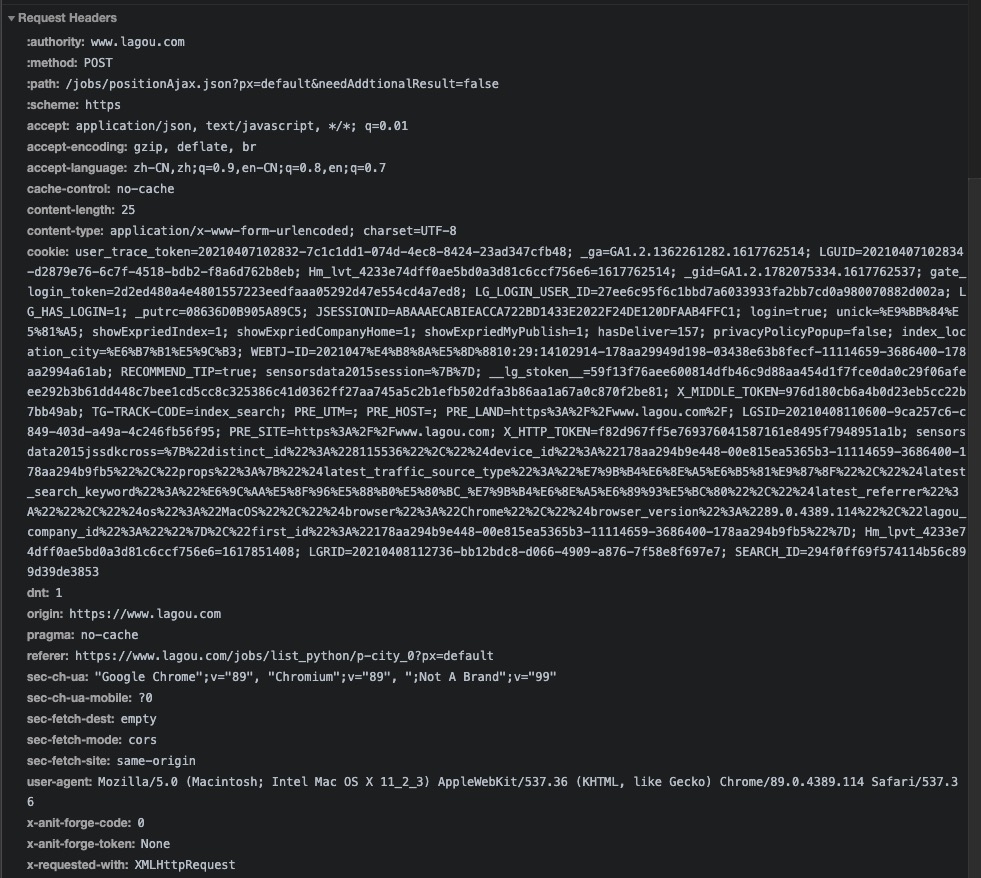 这时候我看到一长串的东西叫做cookie,大部分网站的登录态就是他了,我不管里面包含了什么数据,我尝试复制下来写进请求头,还有user-agent看到没,这个是像服务端表达我是谁,我用的什么设备对你进行的访问,这个也要一并写入请求头
这时候我看到一长串的东西叫做cookie,大部分网站的登录态就是他了,我不管里面包含了什么数据,我尝试复制下来写进请求头,还有user-agent看到没,这个是像服务端表达我是谁,我用的什么设备对你进行的访问,这个也要一并写入请求头
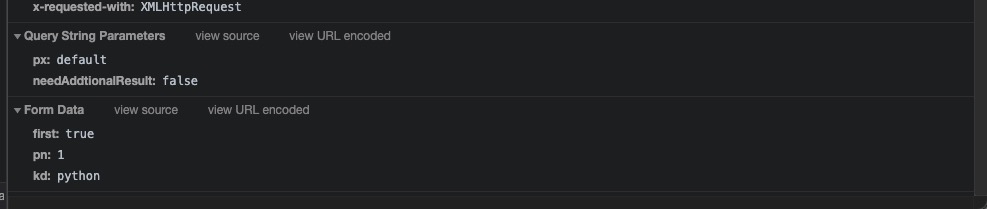 还有POST请求一定会有的request Data,但是仅仅是data吗,我发现他竟然有GET请求的params数据。所以我不仅仅要组装一个from data数据,也要组装一个params数据,我们主要分析form-data中的数据,这个才是控制我们搜索出来的结果集的一个重要参数
first顾名思义,首先,第一,这里为true,为真,很明显这是一个非必要参数,代表是否是第一页,但是我们保持一个前端参数的不可信原理,这个就是一个非必要参数
pn,我尝试打开第二页并分析他们的请求数据发现,pn变成2了,很明显的这就是一个必要性参数,页数
kd,虽然我一眼就猜到了这个参数的意义,但是我还是重新请求了一遍其他的,然后发现他果然也是一个必要性参数,搜索的关键词。
还有POST请求一定会有的request Data,但是仅仅是data吗,我发现他竟然有GET请求的params数据。所以我不仅仅要组装一个from data数据,也要组装一个params数据,我们主要分析form-data中的数据,这个才是控制我们搜索出来的结果集的一个重要参数
first顾名思义,首先,第一,这里为true,为真,很明显这是一个非必要参数,代表是否是第一页,但是我们保持一个前端参数的不可信原理,这个就是一个非必要参数
pn,我尝试打开第二页并分析他们的请求数据发现,pn变成2了,很明显的这就是一个必要性参数,页数
kd,虽然我一眼就猜到了这个参数的意义,但是我还是重新请求了一遍其他的,然后发现他果然也是一个必要性参数,搜索的关键词。
import requests
import time,math,os
class Crawler:
def __init__(self):
'''
这里组装的post请求中fomr-data的默认数据
'''
self.first = 'true'
self.pn = 1
self.sid = ''
'''
这是请求的网址,我上面说过的
'''
self.url = 'https://www.lagou.com/jobs/positionAjax.json'
'''
这里组装的就是请求头了,有我说过的cookie数据,也有我说过的user-agent
'''
self.headerData = {
'origin': 'https://www.lagou.com',
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'cookie': 'xxxx复制下来的一大串'
}
'''
这里是请求中的params数据。一般city为空就是默认值(这都是程序员的默认习惯,为空就是默认值)
'''
self.params = {
'needAddtionalResult': 'false'
}
到这里其实参数就构造完毕了
第一次请求
其实走到这里你会发现,其实我们已经可以抓取到数据了,看代码
import requests
import time,math,os
def exit(msg):
print(msg)
os._exit(0)
class Crawler:
'''构造请求结构'''
def __init__(self):
self.first = 'true'
self.pn = 1
self.sid = ''
self.url = 'https://www.lagou.com/jobs/positionAjax.json'
self.headerData = {
'origin': 'https://www.lagou.com',
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'cookie': 'xxxx复制下来的一大串'
}
self.params = {
'needAddtionalResult': 'false'
}
'''请求的方法'''
def first(self,key):
postData = {
'first': self.first,
'pn': self.pn,
'kd': key
}
response = requests.post(url = self.url,headers = self.headerData,params = self.params,data = postData)
return response
if __name__ == '__main__':
key = 'python'
retractor = Crawler()
data = retractor.first(key)
记录跑到的数据
其实有很多方式啦,推荐是用mysql或者mongodb。当然也可以文件式存储。比如xls,txt。我这里就是用的比较简单的文件式存储,写成一个json文件保存下来,方便我第二次使用
def writeJson(fileName, jsonData):
data = json.dumps(jsonData)
f = open(fileName + '.json', 'w')
f.write(data)
f.close()
按照翻页数据爬取(全代码向crawler.py)
import requests
import time,math,os
import json
def exit(msg):
print(msg)
os._exit(0)
def writeJson(fileName, jsonData):
data = json.dumps(jsonData)
f = open(fileName + '.json', 'w')
f.write(data)
f.close()
class Crawler:
'''
需要獲取的數據一共有
公司名稱 公司鏈接 發佈日期 崗位職責描述 工作地點
工作性質 工作經驗 最低學歷 福利標籤
職位名稱 職位月薪 職位類別 職位鏈接
'''
def __init__(self):
self.first = 'true'
self.pn = 1
self.sid = ''
self.url = 'https://www.lagou.com/jobs/positionAjax.json'
self.headerData = {
'origin': 'https://www.lagou.com',
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'cookie': 'xxxx复制下来的一大串'
}
self.params = {
'needAddtionalResult': 'false'
}
def getPage(self,key):
'''
獲取key值產生的結果總共有多少條信息
'''
# 先休息五秒,防止拉勾的防爬機制產生
time.sleep(5)
#重組post提交數組
postData = {
'first': self.first,
'pn': self.pn,
'kd': key
}
response = requests.post(url = self.url,headers = self.headerData,params = self.params,data = postData)
if response.status_code == 200:
data = response.json()
return data['content']['positionResult']['resultSize'],data['content']['positionResult']['totalCount']
else:
exit('未知錯誤')
def getPageInfo(self,pn,key):
# 先休息五秒,防止拉勾的防爬機制產生
time.sleep(5)
print('第' + str(pn) + '頁')
if pn != 1:
self.first = 'false'
# 重組post提交數組
postData = {
'first': self.first,
'pn': self.pn,
'kd': key
}
response = requests.post(url=self.url, headers=self.headerData, params=self.params, data=postData)
if response.status_code == 200:
data = response.json()
i = 1
for one in data['content']['positionResult']['result']:
index = i * pn
oneData = {
'id' :index,
'companyName' :one['companyFullName'],
'companyLink' :'https://www.lagou.com/gongsi/v1/' + str(one['encryptId']) +'.html',
'releaseDate' :one['createTime'],
'jobsDescribe':'',
'jobsAddress' :one['city'] + '-' + str(one['district']) ,
'jobNature':one['jobNature'],
'jobsExp' :one['workYear'],
'degreeReq' :one['education'],
'welfare' :one['positionAdvantage'],
'positionName':one['positionName'],
'positionWage':one['salary'],
'positionCate':one['firstType'] + '|' + one['secondType'],
'positionLink':'https://www.lagou.com/jobs/' + str(one['positionId']) + '.html?show='
}
jsonData.append(oneData)
i = i + 1
else:
exit('未知錯誤')
if __name__ == '__main__':
key = 'python'
startTime = time.time()
# 獲取總頁數
retractor = Crawler()
pageSize,total = retractor.getPage(key)
pageNum = int(math.ceil(total/pageSize))
jsonData = []
# 循環的開始,獲取每一頁數據
for page in range(0, int(pageNum)):
page = page + 1
retractor.getPageInfo(page,key)
writeJson(key+'Data',jsonData)
endTime = time.time()
print("共花费{}时间完成爬取!".format(endTime - startTime))
----------end
本文为ctexthuang原创文章,转载请注明来自ctexthuang_blog

