网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取网络上信息的程序或者脚本。 人人都说python强,写爬虫方便,机器学习库多。但是,我今天非要反其道而行之,用php的爬虫框架来写写爬虫。 QueryList是一个基于phpQuery的PHP通用列表采集类,得益于phpQuery,让使用QueryList几乎没有任何学习成本,只要会CSS3选择器就可以轻松使用QueryList了,它让PHP做采集像jQuery选择元素一样简单。
安装与简单的演示
安装 选择用composer来安装composer require jaeger/querylist1.当然这个要会composer并且 PHP >= 7.0,如若没有,而且不会使用composer,请下载QueryList3.0版本http://v3.querylist.cc ps:QueryList3支持php5.3以及手动安装。2.如果composer安装速度太慢,可以尝试执行下面命令更换国内镜像composer config -g repo.packagist composer https://packagist.phpcomposer.com</blockquote>
</blockquote>
简单代码演示
一方通行的关注者的信息吧
前置需求
<li>获取编码格式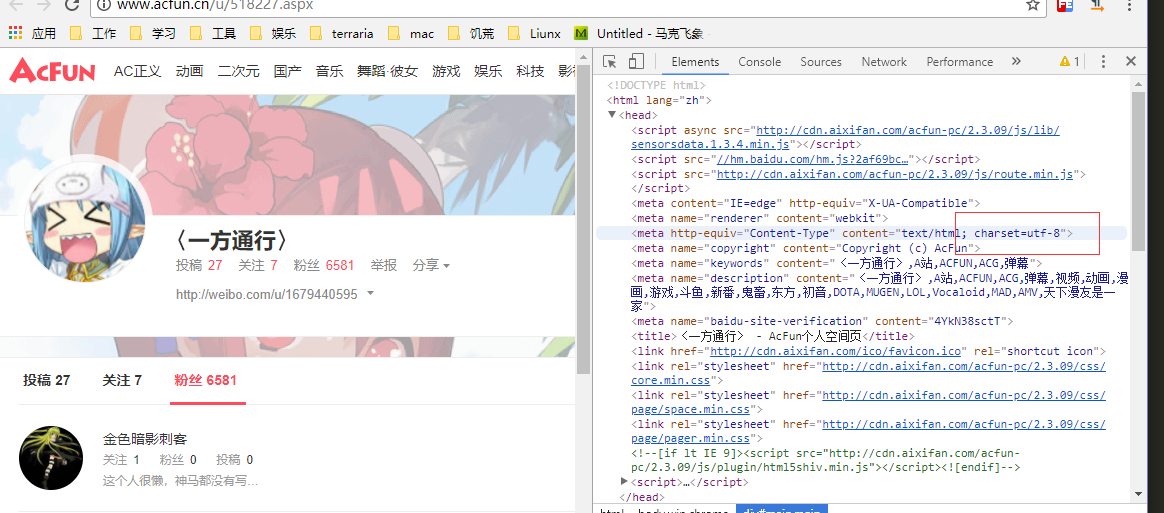
avatar
</li>
<li>获取html信息
avatar
</li> </ol> 简易代码显示</blockquote> </blockquote>
use QL\QueryList;
//设定输出文字的字符集
header("Content-type: text/html; charset=utf-8");
//采集某页面所有的超链接和超链接文本内容
//可以先手动获取要采集的页面源码
$html = file_get_contents('http://www.acfun.cn/u/518227.aspx');
//然后可以把页面源码或者HTML片段传给QueryList
//设置采集规则
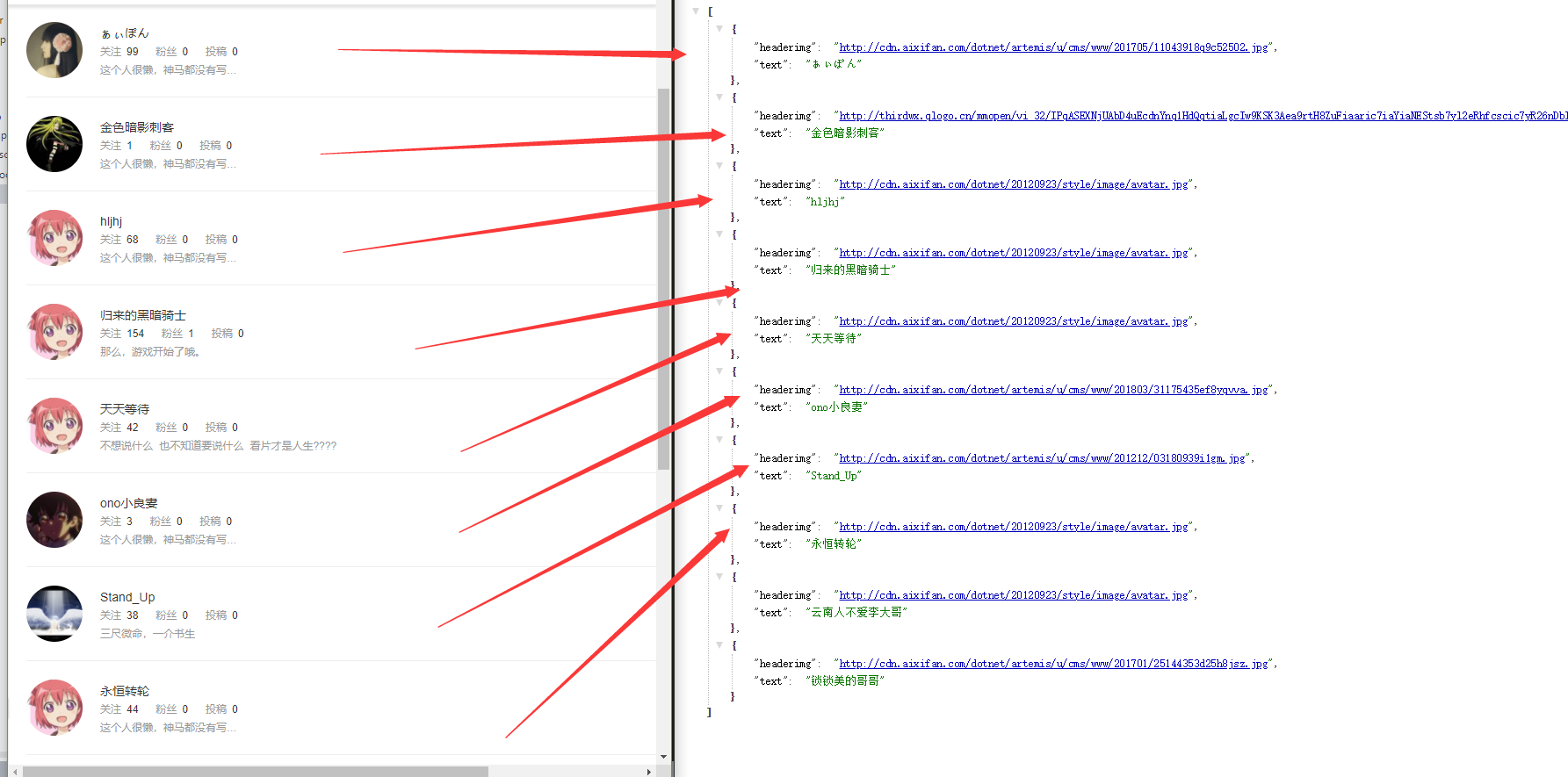
$rule = [
// 采集关注者a标签的href属性
'headerimg' => ['div#flowedlist div.contentView figure div.fl a img','src'],
// 采集关注者a标签的文本内容
'text' => ['div#flowedlist div.contentView figure div.fl a.name','text']
];
//通过封装的方法获取所有数据
$data = QueryList::html($html)->rules($rule)->query()->getData()->all();
//打印结果
print_r($data);
至此,就成功的爬取了一些数据了
avatar
任务式爬取图片的PHP实现(自动下载到本地)
讲真,我也不废话了。直接上代码 哦对了。忘记说了,最好是php-cli模式下运行哦
CodeBlock Loading...
接下来在命令行模式中找到文件运行在命令行模式下输入
- 用户需要把php加入环境变量中才可以在命令行执行
php 你的文件名.php静静等待一段时间,等代码执行完毕。你就会发现,你的文件夹出现了一个新的
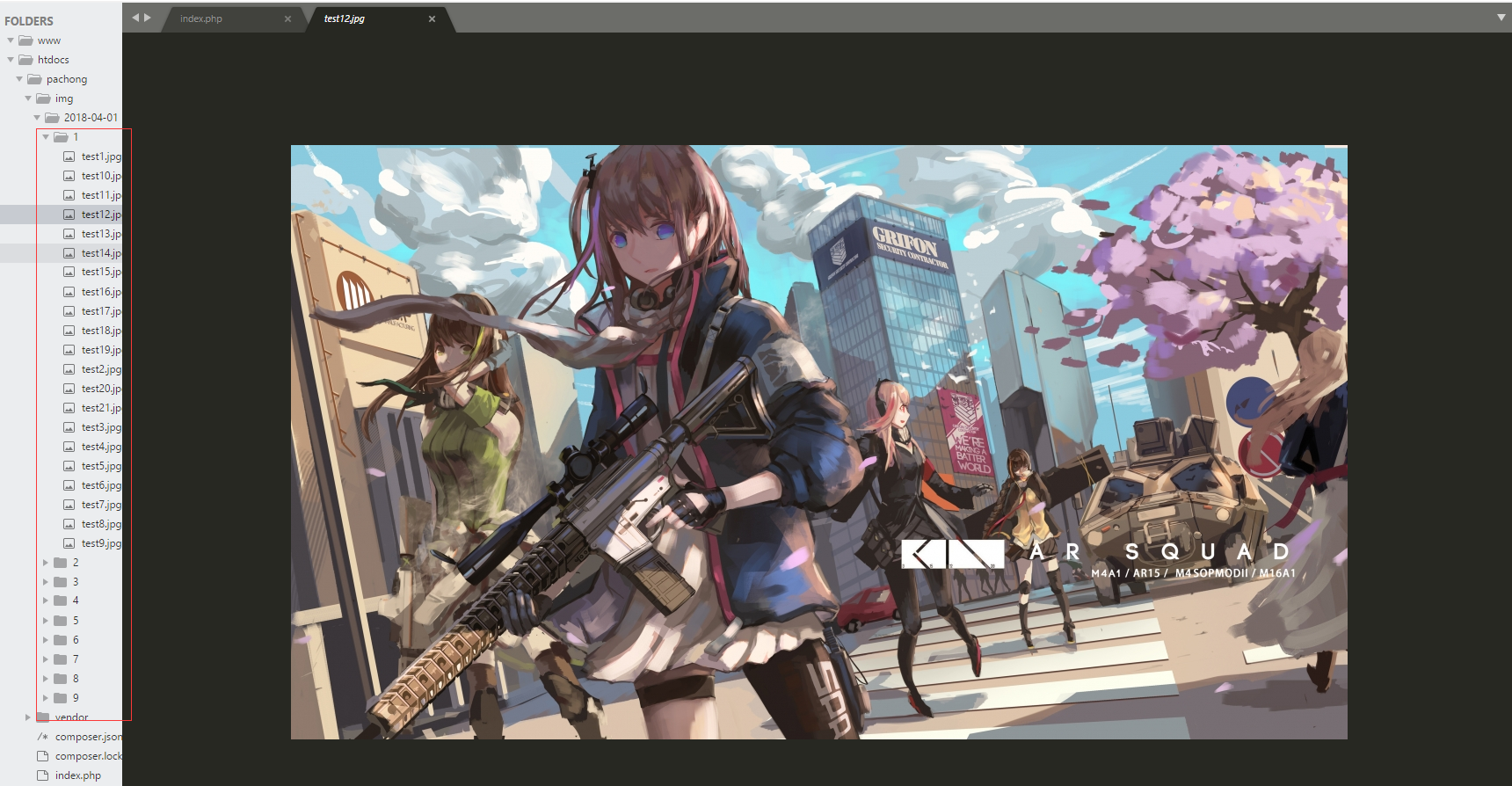
- 如图所示:
avatarimg>date>num的文件夹,里面就是你爬下来的图片了!!!
avatar