一、Redis介绍
最近在做到项目的时候需要一个难题,因为用户需要建立一个量级的计时器用于功能使用。可是通过Linux系统的Crontab达到的效果不佳不适合长期使用。
举个列子证明一下,比如1个用户建立1个定时任务。那我2个用户建立2个,要是1000个用户那就要建立1000个定时任务。这样子Crontab就不可能做到或者说不应该这么去做,会消耗浪费大量的资源。于是乎我只能找寻其他的方法来解决这个问题。我想到了redis的key可以限定时间消失。so在消失的时候能否回调消息以方便进行处理。
然后我去redis官网找有没有这些方面的功能或者插件。所以最终找到了redis>2.8.0版本,推出的一个新的特性--键值空间消息,也就是Redis Keyspace Notifications。
二、Redis Keyspace Notifications介绍
这个究竟是什么东西呢,比如Redis里面有一些事件的发生。就好比如键值到期,键值删除。然后可以配置一些东西好让我们知道Redis一旦触发某些特定的事件返回给我们这些消息。
所以我们的流程呢就是给Redis的db设置过期事件回调,然后我这边写回调通知后的消费逻辑就好了。
三、如何使用
默认情况下键值空间通知功能默认是处于关闭状态下的,所以你需要打开。
打开有两种方式,比如
1.是通过修改redis.conf文件
2.使用CONFIG SET命令还开启功能
notify-keyspace-events可以与任意表中字符组合,指定了服务器应该发送哪些类型的通知
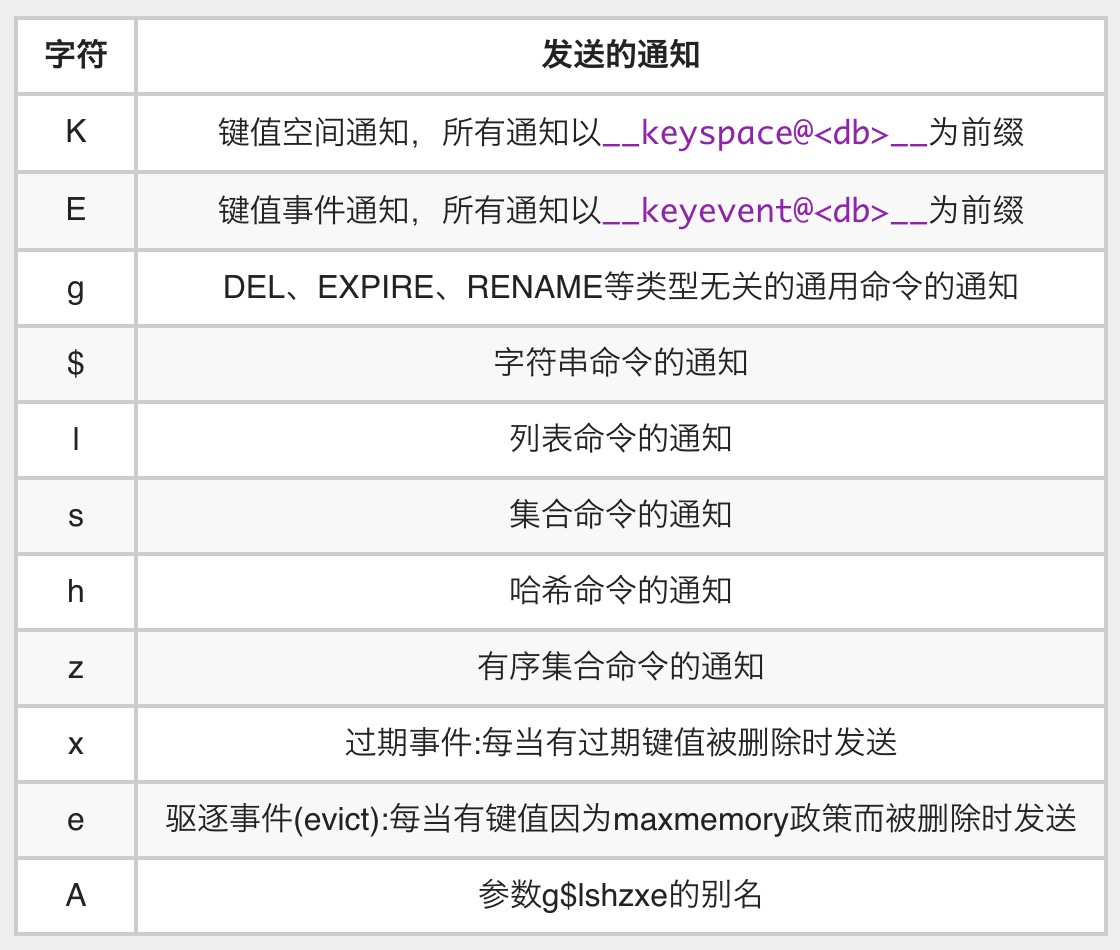
1583227939583.jpg
输入的参数中至少要有一个K或者E,否则的话,不管其余的参数是什么 都不会有任何通知被分发。将参数设为字符串 "AKE" 表示发送所有类型的通知。监听过期事件需要设置Redis 配置文件notify-keyspace-events "Ex"
四、代码中使用
$ redis-cli config set notify-keyspace-events KEA//先设置打开回调通知
监听器psubscribe.php
/**
* Created by PhpStorm.
* Author: ctexthuang
* Date: 2019/9/6
* Time: 11:21 上午
* FileName: psubscribe.php
*
*
* ┌─┐ ┌─┐
* ┌──┘ ┴───────┘ ┴──┐
* │ │
* │ ─── │
* │ > < │
* │ │
* │ ... ⌒ ... │
* │ │
* └───┐ ┌───┘
* │ │
* │ │
* │ │
* │ └──────────────┐
* │ │
* │ ├─┐
* │ ┌─┘
* │ │
* └─┐ ┐ ┌───────┬──┐ ┌──┘
* │ ─┤ ─┤ │ ─┤ ─┤
* └──┴──┘ └──┴──┘
* 神兽保佑
* 代码无BUG!
*/
class Redisv{
private $redis;
//redis connect function
public function __construct($host = '127.0.0.1',$port = 6379,$password = 545593){
$this->redis = new Redis();
$this->redis->connect($host,$port,$password);
}
//To subscribe to function
public function psubscribe($patterns = array(), $callback)
{
$this->redis->psubscribe($patterns, $callback);
}
//Detection timeout function
public function setOption()
{
$this->redis->setOption(\Redis::OPT_READ_TIMEOUT, -1);
}
}
//require_once './Redis.class.php';
$redis = new \Redisv();
// 解决Redis客户端订阅时候超时情况
$redis->setOption();
$redis->psubscribe(array('__keyevent@0__:expired'), 'keyCallback');
// 回调函数,这里写处理逻辑
function keyCallback($redis, $pattern, $chan, $msg)
{
echo "Pattern: $pattern\n";
echo "Channel: $chan\n";
echo "Payload: $msg\n\n";
}